前言
最近想起GitChat的会员要过期了,但是之前购买的达人课只看了一部分,过期不能看就很可惜了,毕竟有些课程质量还是挺好的,所以就想着把课程下载下来拉到本地去看,但是Gitchat的课程并不能够把整个课程下载,需要单个单个的下载,单纯的靠人力处理就只会浪费时间,更何况我是个小coder,尽然希望通过代码来实现,机器能做就就让机器去做,所以就想起了通过爬取的方式下载下来。
也许你会问为什么会想到爬虫实现,首先了解下什么是爬虫,从定义上来说,爬虫是通过脚本请求网页并分析网页来提取有效信息的一种行为,我现在的需求就是能够希望获取到所有的课程并下载,其中最重要的一点就是课程信息的获取,毫无疑问爬虫是能够实现的并且是最佳的实现方式。
技术选型
- 浏览器环境
因为这次爬取都是需要基于浏览器环境进行的,所以需要有浏览器环境的支持,目前达到要求的可选有puppeteer、phantomjs、selenium-webdriver;但是后两者环境配置复杂并且难用的api决定了难以担当此任;
- 解析文档
毋庸置疑cheerio是目前node端爬虫最好用的dom解析库,它具备了像 jquery 一样遍历跟操作DOM元素的能力,当然它只拥有解析能力,并没有事件函数;
遇到的问题
也许你会问,为什么爬虫能够解决我的问题?
登录账号问题
首先,Gitchat是没有输入框登录,它的登录方式是通过微信扫描二维码来登录,也就是和微信服务有一层绑定关系,所以第一步要解决的就是怎么绕过这层扫描登录;所以我首先想到的就是有没有通过cookie来校验登录状态,通过分析登录前后的cookie的,发现其中的一些差异极有可能是和账号有关的,所以直接把登录态的cookie获取出来来模拟登录,没想到真的成功了。。。
跳转到具体课程
通过对页面的分析得知,Gitchat里面的每个大课下的小课跳转都是通过js的onclick函数来动态控制的,所以需要分析onclick函数下的跳转规律,发现下面一行代码
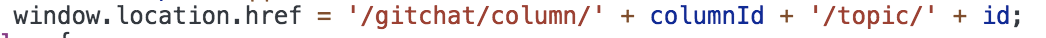
然后通过正则把跳转需要的`columnId`、`id`拿到,最终也实现了跳转课程
获取下载链接
最初的想法是通过puppeteer来模拟点击的方式来跳转下载链接的,但是奇怪的是跳转后的page并不是之前创建的page,所以并不能够获取上下文环境,所以对应的api也就不能用了,所以这种方式失败了;最后分析整个文档得知下载的链接隐藏在了script里面,所以最终还是通过正则表达式匹配出来。
没有PDF下载的情况
某些课程下其实并没有提供下载功能,所以并不能够通过获取pdf链接的方式来下载,所以只能够寻求别的方法,想到既然chrome能够做的puppeteer都能做,那当然想到截屏的功能了,所以找了下puppeteer截图并打印的api,最终实现。
爬虫实现
1)初始化浏览器
利用puppeteer来创建浏览器环境
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
async function openBrowser() {
const browser = await puppeteer.launch({
headless: true,
});
const page = await browser.newPage();
return {
browser,
page,
}
}
|
2) 跳转到首页并设置登录
通过对比登陆前后的cookie,分析出customerId、customerToken是确定是否登录的参数,所以在跳转到首页后立马设置cookie值,保证下面的请求都是已登录状态
1
2
3
4
5
6
7
8
9
10
11
|
async function gotoGitchat(page, browser) {
await page.goto(GIT_CHAT_URL, { timeout: 6000000 });
await page.evaluate(() => {
document.cookie="customerId=your id";
document.cookie="customerToken=your token";
Promise.resolve();
});
}
|
3) 获取已购课程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
async function getOrderColumns(page) {
let columns = await page.goto(`${GIT_CHAT_URL}/gitchat/ordered/columns`, { timeout: 6000000 });
let columnContent = await page.content();
const $ = cheerio.load(columnContent);
const column = $('.column');
return _.map(column, (item, index) => {
return {
link: item.attribs.href,
title: $('.column .columnInfo .columnTitle')[index].children[0].data,
};
});
}
|
4) 获取下载的URL
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
async function getDownLoadUrl(page, link) {
const column = await page.goto(`${GIT_CHAT_URL}${link}`, { timeout: 6000000 });
const topicContent = await page.$$('.columnTopics .topicTitle');
const pageContent = await page.content();
const $ = cheerio.load(pageContent);
return _.reduce($('.topicTitle'), (result, item, index) => {
const clickCallback = $('.topicTitle').eq(index).attr('onclick');
const title = $('.titleText').eq(index).text();
const idsString = clickCallback.replace(/(\[)|(\])|\s+|\'|(\()|(\))/g, '');
const ids = idsString.replace('clickOnTopic', '').split(',');
result.push({
link: !_.isEmpty(ids) ? `${GIT_CHAT_URL}/gitchat/column/${ids[1]}/topic/${ids[0]}` : '',
title,
});
return result;
}, []);
}
|
5) 下载课程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
async function downColumns(page, targetLink) {
try {
const downLoadInfo = await getDownLoadUrl(page, targetLink.link);
console.log(`【创建${targetLink.title}文件夹】`)
await fs.mkdir(path.join(__dirname, '/columns', targetLink.title), function (err) {
if (err) throw err;
});
for (let i = 0; i < downLoadInfo.length; i++) {
console.log(`【获取第${i}课下载链接】`);
const contentRegx = /window.location.href = '([^']+)'/;
const downUrl = downLoadInfo[i].link;
const downloadPath = path.join(__dirname, 'columns', targetLink.title, `${downLoadInfo[i].title}.pdf`);
const gotoDownload = await page.goto(downUrl, { timeout: 6000000 });
const downContent = await page.content();
if (!contentRegx.test(downContent)) {
console.log('【没有下载链接】:即将打印成PDF');
await page.$eval('body', body => {
body.querySelector('#header').style.display = 'none';
body.querySelector('#commentModal').nextSibling.style.display = 'none';
Promise.resolve();
});
await page.emulateMedia('screen');
await page.pdf({ path: downloadPath });
console.log(`【打印完成】: ${downLoadInfo[i].title}`);
await sleep(1000);
continue;
}
const url = downContent.match(contentRegx)[1];
console.log(`【下载链接】:${url}`);
const downLoadReq = request.get(url);
downLoadReq.pipe(fs.createWriteStream(downloadPath));
console.log('【下载完成】');
await sleep(1000);
}
} catch (e) {
console.log(`【ErrorTip】: ${e}`);
}
};
|
总结
这篇文章主要是讲解一下爬虫实现思路和我实现过程遇到的问题,并没有涉及太多的puppeteer的api操作,具体的操作会在学习总结那里做记录,并且实现代码也有更好的写法,比如可以并发下载(通过打开多个窗口实现)、加入重试机制等。但是毕竟只是为了解决自己的需求,怎么简单怎么来嘛哈哈。